 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning or Self-supervised Learning? A Tale of Two Pretraining Paradigms
Jun 19, 2020
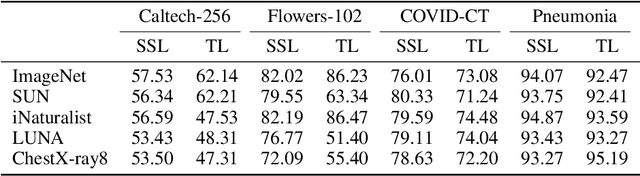
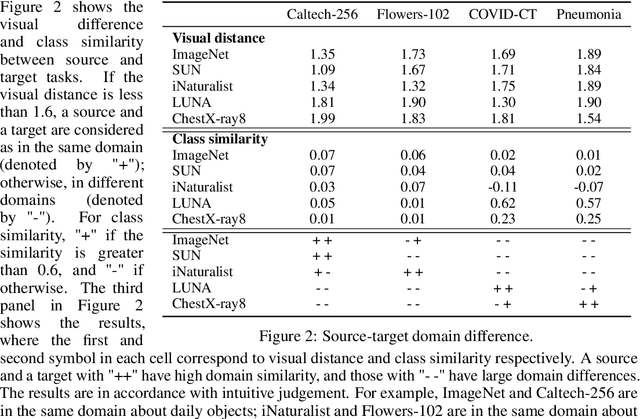
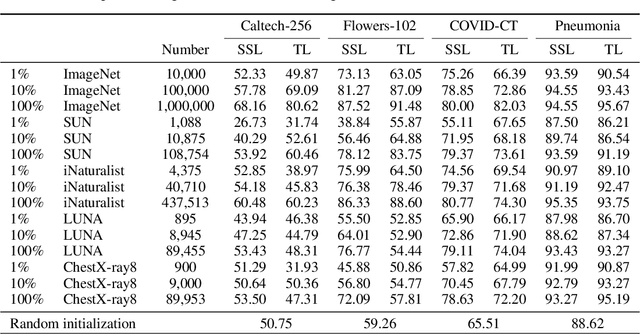
Pretraining has become a standard technique in computer vision and natural language processing, which usually helps to improve performance substantially. Previously, the most dominant pretraining method is transfer learning (TL), which uses labeled data to learn a good representation network. Recently, a new pretraining approach -- self-supervised learning (SSL) -- has demonstrated promising results on a wide range of applications. SSL does not require annotated labels. It is purely conducted on input data by solving auxiliary tasks defined on the input data examples. The current reported results show that in certain applications, SSL outperforms TL and the other way around in other applications. There has not been a clear understanding on what properties of data and tasks render one approach outperforms the other. Without an informed guideline, ML researchers have to try both methods to find out which one is better empirically. It is usually time-consuming to do so. In this work, we aim to address this problem. We perform a comprehensive comparative study between SSL and TL regarding which one works better under different properties of data and tasks, including domain difference between source and target tasks, the amount of pretraining data, class imbalance in source data, and usage of target data for additional pretraining, etc. The insights distilled from our comparative studies can help ML researchers decide which method to use based on the properties of their applications.
Identifying Radiological Findings Related to COVID-19 from Medical Literature
Apr 04, 2020
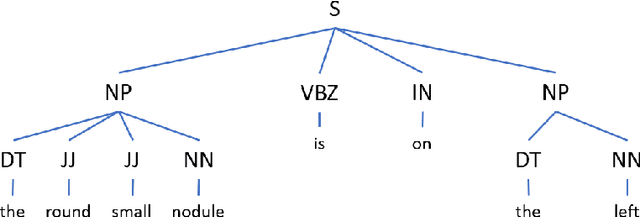

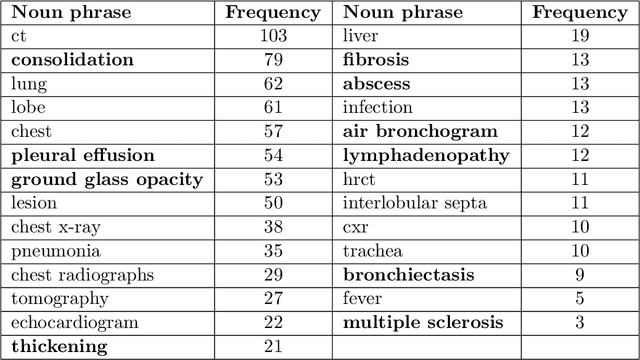
Coronavirus disease 2019 (COVID-19) has infected more than one million individuals all over the world and caused more than 55,000 deaths, as of April 3 in 2020. Radiological findings are important sources of information in guiding the diagnosis and treatment of COVID-19. However, the existing studies on how radiological findings are correlated with COVID-19 are conducted separately by different hospitals, which may be inconsistent or even conflicting due to population bias. To address this problem, we develop natural language processing methods to analyze a large collection of COVID-19 literature containing study reports from hospitals all over the world, reconcile these results, and draw unbiased and universally-sensible conclusions about the correlation between radiological findings and COVID-19. We apply our method to the CORD-19 dataset and successfully extract a set of radiological findings that are closely tied to COVID-19.